안녕하세요! 저번 글에서는 API를 사용하여 데이터를 가쟈오는 글에 대해 다뤘었는데요
2023.02.18 - [Project] - [ 환경방사능 예측 프로그램 ] 1. 공공 데이터 포털 API 가져오기
[ 환경방사능 예측 프로그램 ] 1. 공공 데이터 포털 API 가져오기
안녕하세요! 현재 진행 중인 프로젝트 과정에 대한 글을 올려볼까 합니다. 방사능 분야의 인공지능 전문가가 되기 위한 첫 프로젝트라고 할 수 있겠는데요 이번 프로젝트에서는 환경 방사선 API
foxyprogramming.tistory.com
생성된 csv 파일을 확인하고, 각각의 csv 파일을 하나로 병합해주는 방법에 대한 글을 작성하려고 합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns사용하든 안하든 일단 선언부터 하고 봅니다 ㅋㅋㅋ 인공지능 공부하시는 분들은 공감하실 수도 있겠지만, 이제는 그냥 습관이 돼버렸네요
date_measure = pd.read_csv('data/date_measure.csv')
date_measure.head()
각각의 컬럼이 무엇을 의미하는지 데이터포털 사이트에서 참고하여 주석처리 해줍니다.
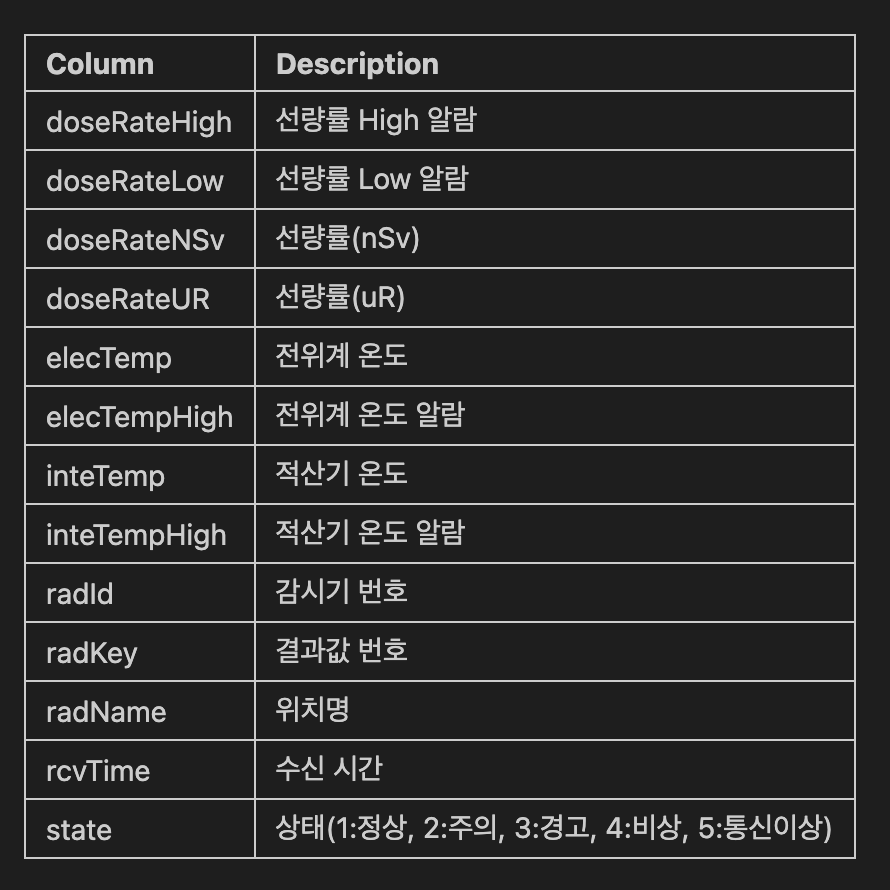
이후 각각의 컬럼의 값을 확인하기 위해
date_measure['doseRateHigh'].value_counts()를 사용하였고, 몇몇 컬럼의 경우에는 단일 값을 가지고 있으므로, 이후 삭제를 할 예정이였고, 모든 컬럼에 대한 정보를 확인하여 다음처럼 주석처리를 해줬습니다.

1. 데이터 전처리
date_measure.drop(['Unnamed: 0','doseRateHigh','doseRateLow','elecTempHigh','inteTempHigh','radKey'],axis=1, inplace=True)
date_measure.head()
필요없는 컬럼은 삭제하여 필요한 부분만 사용가능해졌네요.
이후 다른 csv 파일도 동일하게 적용하여, 병합할 준비를 해줍니다.
2. 데이터 병합
a = pd.merge(date_measure, sensor,how='inner')
a데이터는 공통 인덱스를 기준으로 통합하는 Inner Join을 사용하였습니다.
radId와 radName을 기준으로 통합했네요
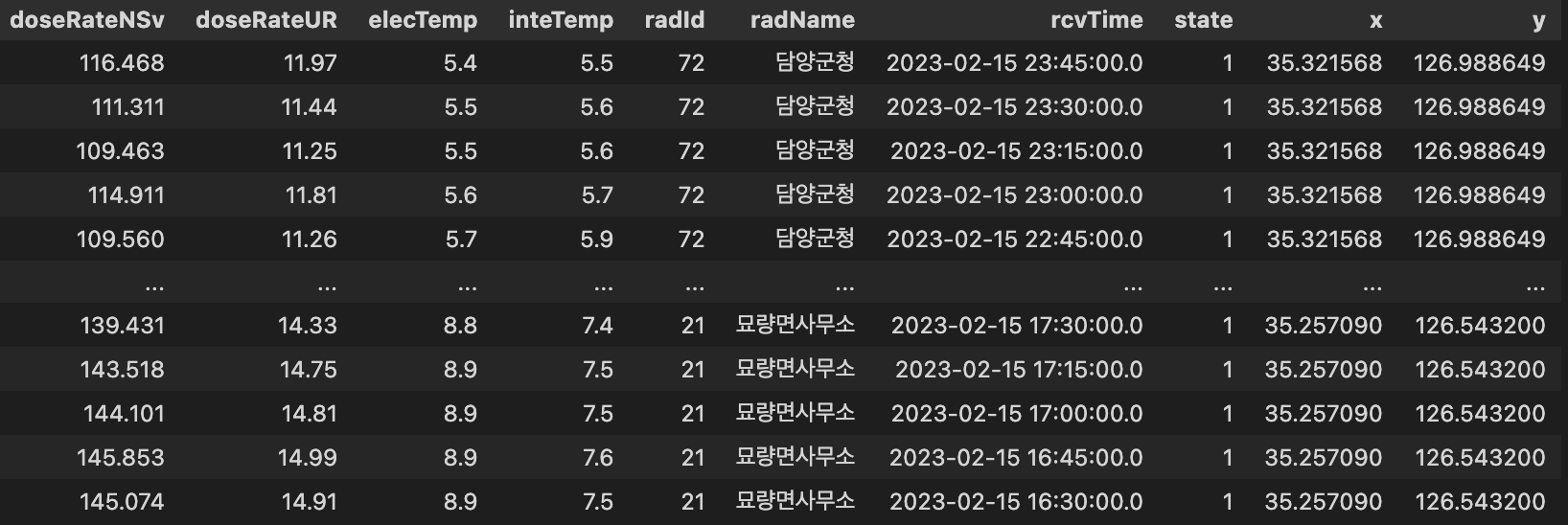
이렇게 전처리 후 병합된 파일을 csv 파일로 또 내보내줍니다.
a.to_csv('new_data/df.csv')이제 df 라는 파일 하나로 프로젝트를 진행하면 되겠네요!
이상으로 데이터 전처리 및 통합이 완료되었습니다.

이후 프로젝트에서는 음.. folium을 이용하여 지도 시각화를 진행할 예정이고,
가능하다면 각 측정 지점에서의 예측값을 띄어볼 생각입니다.
더해서 각 컬럼간의 상관성도 분석해볼 예정이고,
이후에는 선량률을 예측하는 프로그램을 만들어볼 계획입니다.
또 다른 성과가 있다면 다음 글에서 알려드리도록 하겠습니다. 감사합니다!
'Project' 카테고리의 다른 글
| [ 환경방사선 예측 프로그램 ] 3. LSTM 모델 활용하여 예측하기 (0) | 2023.03.08 |
|---|---|
| [ 환경방사능 예측 프로그램 ] 1. 공공 데이터 포털 API 가져오기 (0) | 2023.02.18 |
| [웹디자인 기능사 실기] 기출문제(2) (0) | 2022.08.09 |
| [웹디자인기능사 실기] 기출문제(1) (2) | 2022.08.04 |



