
"Change Point Enhanced Anomaly Detection for IoT Time Series Data"는 변화 지점 검출을 통해 IoT 시계열 데이터의 오탐을 줄이고 이상 탐지의 정확성을 높이는 새로운 규칙 기반의 의사 결정 시스템을 제안한 논문입니다. 아래는 위 논문의 요약 및 설명입니다.
Abstract
갑작스러운 변화 지점을 정상 행동과 함께 탐지하고 이를 통해 비정상 행동, 즉 이상치를 구별하는 것은 오탐률을 최소화하고 예측 및 예보를 위한 정확한 기계 학습 모델을 구축하는 데 중요한 단계입니다. 이 논문은 IoT 센서에서 수집된 수자원 데이터에 초점을 맞추어, 변화 지점 검출을 통한 시계열 데이터의 이상 탐지를 향상시키는 새로운 자동화된 지능형 규칙 기반 의사 결정 지원 시스템을 제안합니다. 이 시스템은 변화 지점이 도입한 오탐을 제거하고 실제 이상을 자동으로 감지하는 파이프라인을 사용합니다. 위 시스템은 5가지 이상 탐지 알고리즘과 5가지 변화 지점 검출 알고리즘을 통합합니다.
1. Introduction
이 연구의 초점은 수자원 관리와 네트워크 분배를 위한 시계열 데이터 분석에 있습니다. 수자원 관리 시스템은 최적의 운영 및 유지 관리를 위해 정확해야하며 적시의 데이터에 크게 의존합니다. IoT 센서에서 수집된 수자원 데이터의 시계열 데이터를 분석하여 변화 지점을 식별하고, 이를 통해 이상 탐지의 정확성을 높이는 방법을 연구합니다. Change Points Detection은 분석된 시계열 데이터 스트림에서 예상치 못한 중요한 변화를 나타내며, 이는 정상 행동을 나타내며 이상이 아닙니다.
IoT 시계열 데이터의 이상 탐지를 향상시키는 새로운 규칙 기반 의사 결정 시스템을 제안합니다. 이 아키텍처는 변화 지점에 의해 도입된 오탐을 제거하고 실제 이상을 감지하는 파이프라인을 사용합니다. 5가지 이상 탐지 알고리즘으로 Gaussian Distribution, K-Means, Isolation Forest, One-Class SVM, AutoEncoder와 5가지 Change Points Detection으로 Window-based segmentation, binary segmentation, bottom-up segmentation, Pruned Exact Linear Time, exact segmentation dynamic programming model을 사용합니다.
(2. Related Work 부분은 생략하였습니다)
3. Methodology
Time Series Definition
시계열 데이터는 특정 시점에서 기록된 관측값의 집합입니다. 시계열은 이산적 또는 연속적일 수 있습니다.$X = \{x_t|t \in 1, T\}$ 는 랜덤 연속 또는 이산 변수들의 순서로 설명될 수 있습니다. 여기서 $t$는 값이 측정된 시점을 나타내며 $T = |X|$는 $X$의 크기를 나타냅니다.
Components of a Time Series
각 시계열 데이터 포인트 $x_t$는 다음 세 가지 구성 요소로 분해됩니다 :
1. Trend Component $m_t$ : 저주파 변동을 나타내며 이동 평균 또는 스펙트럼 평활화 방법으로 결정될 수 있습니다. 이는 시계열 데이터의 장기적인 변동 경향을 포착합니다.
2. Seasonal Component $s_t$ : 특정 기간(h) 후에 더 안정적인 정상 변동을 나타내는 함수입니다. 이는 데이터에서 주기적으로 나타나는 패턴을 설명합니다.
3. Noise Component $y_t$ : 분석 모델이 데이터를 올바르게 결정했는지 확인하고 미래 값을 예측하는 데 도움이 되는 잔차 부분입니다.
시계열 데이터는 덧셈 분해 함수 또는 곱셈 분해 함수를 사용하여 분해할 수 있습니다 :
1. 덧셈 분해 함수 : $x_t = m_t + s_t + y_t$
2. 곱셈 분해 함수 : $x_t = m_t \cdot s_t \cdot y_t$
Autocorrelation계절 및 추세 구성 요소는 시계열 $X$가 자기 상관되는 경우를 나타냅니다. 이는 $X$가 지연된 버전의 자기 자신과 선형적으로 관련이 있다는 것을 의미합니다. 지연 h에서의 자기 공분산 함수는 다음과 같이 정의됩니다 :
$\gamma x(h) = Cov(X_{t+h}, X_t)$ 여기서 Cov는 공분산 함수입니다. 자기 상관 함수는 다음과 같이 정의됩니다 :
$\rho x(h) = \frac{\gamma x(h)}{\gamma x(0}$
Time Series Outlier Detection
이상치 또는 이상값은 시계열에서 다른 관측값들과 크게 다른 데이터 포인트를 의미합니다. 이상치는 측정의 실수나 데이터의 비정상적인 변화로 인해 발생할 수 있습니다. 이러한 의심스러운 포인트들은 분석 단계에서 잘못된 결론을 피하기 위해 별도로 식별하고 해석해야 합니다.
이상 탐지 문제는 시계열 $X$의 데이터 포인트 $x_t$를 이상치 점수 $s_t$로 랭킹하는 것을 포함합니다. $s_t$ 값이 클수록 $x_t$가 이상치일 가능성이 높아집니다.
Anomaly Detection Algorithms :
1. Gaussian Distribution
Gaussian Distribution 또는 정규 분포는 이상치를 탐지하는 데 사용되는 확률 통계적 접근법입니다. 데이터 포인트가 정규 분포를 따르는지 확인하기 위해 확률 밀도 함수 PDF가 사용됩니다. PDF는 다음과 같이 주어집니다 :

2. K-Means
K-Means는 k개의 유사한 데이터 포인트 클러스터를 만드는 비지도 학습 알고리즘입니다. 클러스터에 속하지 않는 데이터 포인트는 이상치로 표시됩니다. 유클리드 거리를 사용하여 데이터 포인트 $x_t$가 중심 c에 속하는지를 측정합니다.
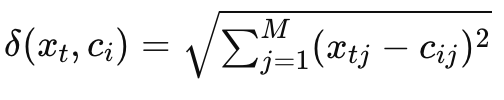
3. Isolation Forest
Isolation Forest는 랜덤 포레스트를 기반으로 한 비지도 이상 탐지 알고리즘입니다. 여러 개의 Isolation Trees를 훈련하여 각 데이터 포인트의 이상치 가능성을 평가합니다. 경로 길이를 이용한 점수 함수는 다음과 같습니다 :
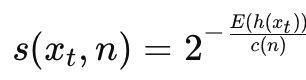
여기서 $h(x_t)$는 루트에서 데이터 포인트 $x_t$까지의 경로 길이이고, $E(h(x_t))$는 평균 경로 길이, $c(n)$는 이진 검색 트리에서의 평균 경로 길이입니다.
4. One-Class Support Vector Machine
One-Class Support Vector Machine은 데이터 세트의 정상 포인트로 구성된 데이터셋에서 훈련된 비지도 학습 알고리즘입니다. OC-SVM은 데이터 세트의 전체에 대한 지원을 추정하는 함수를 모델링합니다. 이 접근법은 데이터 세트에서 대표 포인트를 감지하고 매우 적은 이상치를 분리하는 데 사용됩니다. OC-SVM 함수는 다음과 같습니다:

5. Autoencoder
Autoencoder는 입력 시계열 $X$를 출력 벡터 $\hat{X}$로 재구성하는 신경망입니다. 네트워크는 인코더와 디코더로 구성됩니다. 목표는 각 데이터 포인트 $x_t$에 대해 다음을 최소화하는 것입니다 :

Time Series Change Point Detection
시계열 데이터에서 중요한 변화 지점을 찾는 것은 다양한 응용 분야에서 매우 중요합니다. 특히 IoT(사물 인터넷) 환경에서는 시계열 데이터의 특성이 갑작스럽게 변화하는 지점을 정확히 찾아내는 것이 필수적입니다. Change Point Detection는 이러한 변화를 식별하여 데이터의 의미 있는 분석과 예측을 가능하게 합니다.
Change Point Detection Algorithms :
1. Window-Based Segmentation Model : 이 방법은 시계열 $X$의 데이터 포인트를 따라 슬라이딩 윈도우를 사용하여 두 인접한 시간 창 사이의 차이를 계산합니다. 변화 지점을 감지하기 위해 각 시간 $t$ 인덱스에 대한 차이를 계산합니다.
2. Binary Segmentation Model : 이 모델은 비용 합계를 최소화하는 변화 지점을 탐색합니다.
3. Bottom-up Segmentation Model : 이 방법은 많은 변화 지점에서 시작하여 덜 중요한 지점을 삭제하는 방식으로 작동합니다.
4. Pruned Exact Linear Time Model : 페널티가 선형일 때 정확한 해를 제공합니다.
5. Exact Segmentation Dynamic Programming Model : 동적 프로그래밍을 사용하여 정확한 분할을 제공합니다.
Proposed solution
4. Proposed Solution
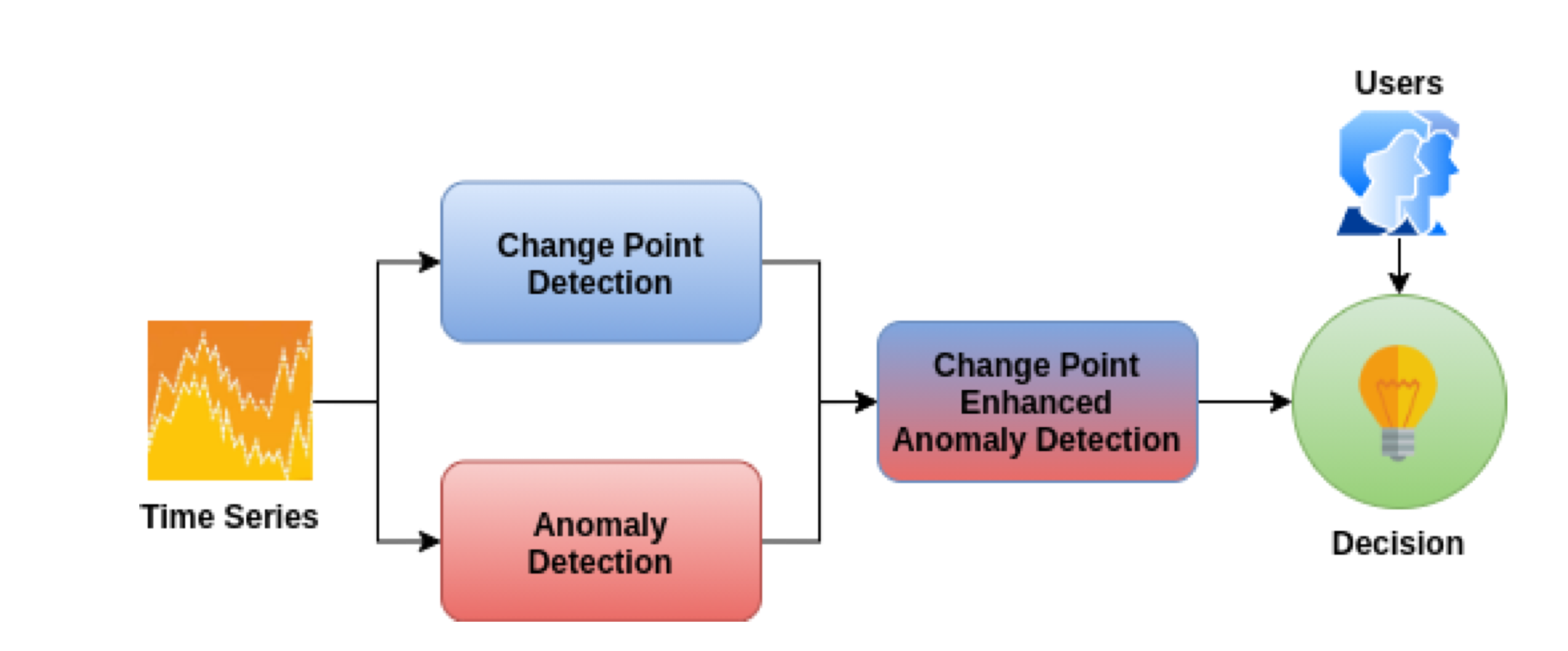
1. Anomaly detection Module :
- Gaussian Distribution: Elliptical Envelope을 공분산 함수로 사용하여 비정상 데이터를 탐지합니다. 이상치의 비율은 0.01로 초기화합니다.
- K-Means: K-Mean++ 알고리즘을 사용하여 K-Means 중심을 초기화하고, Principal Component Analysis를 사용하여 차원을 축소한 후 Elbow Method를 사용하여 최적의 클러스터 수를 결정합니다.
- Isolation Forest: 100개의 Isolation Trees를 사용하여 데이터를 분리합니다.
- One-Class SVM: RTF 커널 함수를 사용하여 데이터를 분류합니다.
- Autoencoders: 13개의 완전 연결된 은닉층을 갖춘 오토인코더를 사용합니다. 각 층의 퍼셉트론 수는 [M, 64, 32, 16, 8, 4, 2, 4, 8, 16, 32, 64, M]이며, 에포크는 100으로 설정합니다.
2. Change Point detection Module :
변화 지점 탐지 모듈은 입력 시계열 데이터 내에서 변화 지점을 감지하기 위해 다양한 기법을 사용합니다.
3. Change Point enhanced Anomaly detection Module :
변화 지점 강화 이상 탐지 모듈은 이전 두 모듈의 출력을 받아 결과를 비교하고 각 데이터 포인트가 이상치일 확률을 계산합니다.

4. Decision Module :
의사 결정 모듈은 이상 탐지와 변화 지점 탐지의 결과를 종합하여 데이터 포인트가 이상치인지 정상인지 결정합니다.
5. Experimental Results
Dataset
- 시간 단위: 1시간
- 변수: Water Consumption
- 총 데이터 포인트: 각 센서당 24개 (하루치 데이터)
- 센서 수: 다수
Results
1. Evaluation
알고리즘의 정확도를 결정하기 위해 Mean Absolute Error를 사용하였으며,
Logistic Regression를 사용하여 예측을 진행하였습니다.
2. Anomaly Deteciton
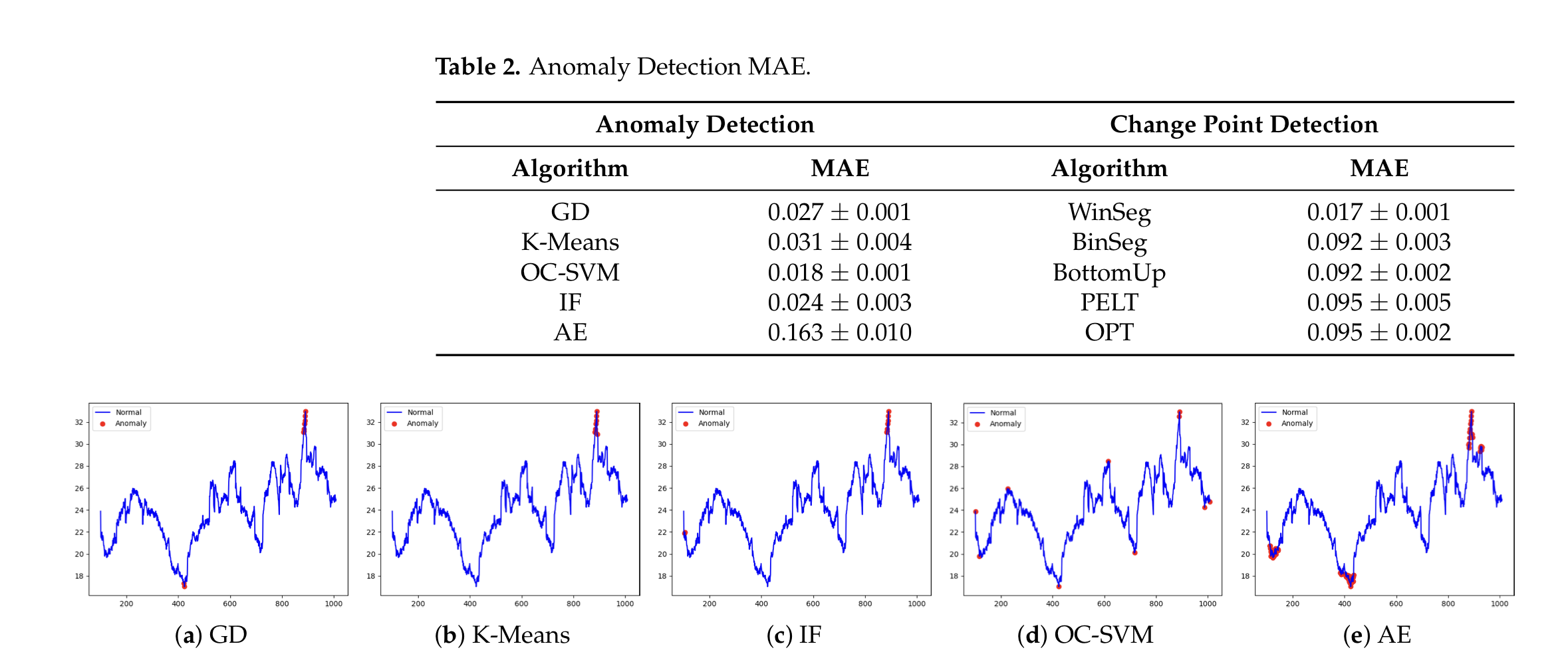
- Overall Performance: 전반적으로 최저 MAE 점수는 OC-SVM 알고리즘이 기록했습니다.(우수)
- Algorithm Performance:
- Gaussian Distribution: MAE = 0.027 ± 0.001
- K-Means: MAE = 0.031 ± 0.004
- OC-SVM: MAE = 0.018 ± 0.001
- Isolation Forest : MAE = 0.024 ± 0.003
- Autoencoder : MAE = 0.163 ± 0.010
3. Change Point Detection

- Overall Performance: 최저 MAE 점수는 WinSeg 알고리즘이 기록했습니다. (우수)
- Algorithm Performance:
- WinSeg: MAE = 0.017 ± 0.001
- BinSeg: MAE = 0.092 ± 0.003
- BottomUp: MAE = 0.092 ± 0.002
- PELT: MAE = 0.095 ± 0.005
- OPT: MAE = 0.095 ± 0.002
4. Change Point Enhanced Anomaly Detection
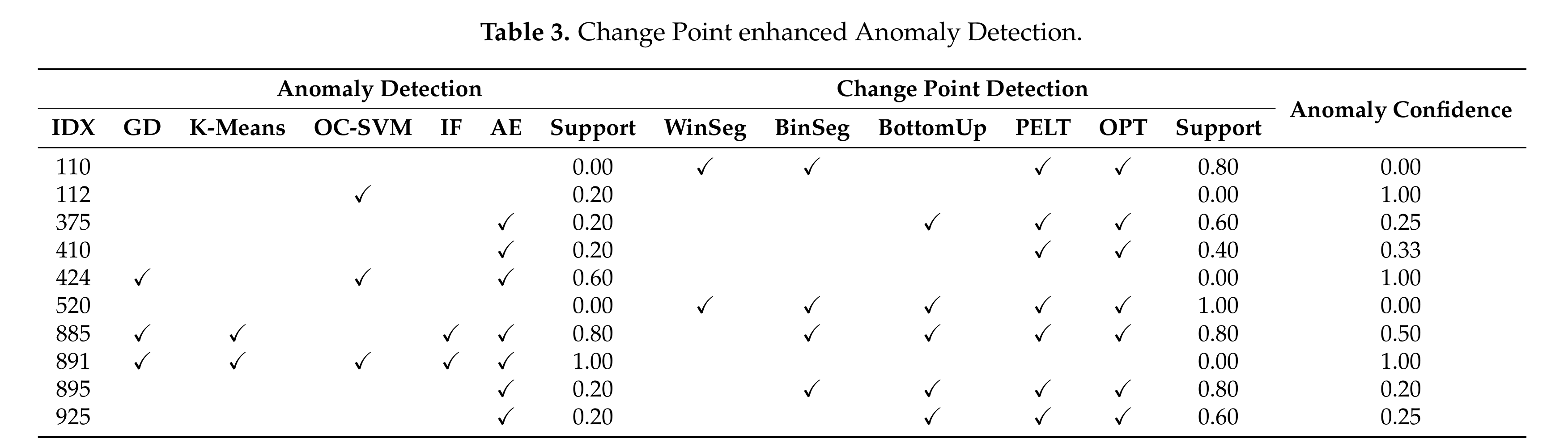
이 실험 결과는 제안된 방법이 다양한 상황에서 어떻게 적용되고 평가되었는지를 보여줍니다. 특히 OC-SVM 알고리즘이 전반적으로 가장 낮은 MAE 점수를 기록하여 효과적인 이상 탐지 성능을 보였으며, 변화 지점 탐지에서는 WinSeg 알고리즘이 가장 우수한 성능을 보였습니다. 이를 통해 변화 지점 탐지와 이상 탐지의 결합이 전체적인 탐지 성능을 향상시킬 수 있음을 확인할 수 있습니다.
6. Discussion
- OC-SVM의 우수한 성능: OC-SVM 알고리즘이 가장 낮은 MAE 점수를 기록하여, 이상 탐지에서 가장 높은 정확도를 보였습니다. 이는 OC-SVM이 비지도 학습에서 강력한 성능을 발휘함을 시사합니다.
- WinSeg의 변화 지점 탐지 성능: 변화 지점 탐지에서는 WinSeg 알고리즘이 가장 낮은 MAE 점수를 기록했습니다. 이는 WinSeg가 시계열 데이터의 중요한 변화를 잘 포착함을 나타냅니다.
- 변화 지점과 이상 탐지의 결합 효과: 변화 지점 탐지와 이상 탐지를 결합한 모듈은 각각의 모듈을 단독으로 사용할 때보다 더 높은 신뢰도를 보였습니다. 이는 변화 지점 정보를 활용하여 이상 탐지의 정확도를 높일 수 있음을 보여줍니다.
- Gaussian Distribution : 비교적 낮은 MAE 점수를 기록했지만, 다른 알고리즘에 비해 성능이 뒤떨어짐.
- K-Means: 클러스터링 기반의 접근법으로 일부 이상치를 잘 탐지했으나, OC-SVM보다 성능이 낮음.
- Isolation Forest: 랜덤 포레스트를 기반으로 하여 일부 데이터셋에서 강력한 성능을 보였으나, 전반적으로 OC-SVM보다 낮은 성능.
- Autoencoders: 높은 MAE 점수를 기록하여, 다른 알고리즘에 비해 성능이 떨어짐.
7. Conclusions
이 논문에서는 IoT 시계열 데이터에 대한 5개의 서로 다른 이상 탐지 알고리즘을 사용하여 이상치를 감지하고, 지원 함수를 사용하여 시계열 데이터 포인트가 실제로 이상치인지 여부를 결정하는 아키텍처를 제안합니다. 동일한 시계열에서 5개의 다른 알고리즘을 사용하여 변화 지점을 감지하고, 데이터 포인트가 실제로 변화 지점인지 여부를 결정하기 위한 계산을 지원합니다. 이 두 가지 support score를 사용하여 데이터 포인트가 이상치일 확률을 계산하고, 이를 통해 규칙 기반 의사 결정 시스템이 자동으로 결정을 내리거나 인간 운영자에게 경고해야 할 필요가 있는지 여부를 판단할 수 있습니다.
