안녕하세요!
23년 6월 24일에 있을 빅데이터 분석기사 실기를 준비하면서 준비를 해도 불안함 마음으로 더 많은 자료를 찾는 분들이 있으실 텐데요
조금이라도 도움이 되고자 Kaggle 데이터를 활용해서 작업형 2 유형을 다뤄보겠습니다!
Kaggle 입문자들에게도 좋을 것 같네요

Heart Failure Prediction
12 clinical features por predicting death events.
www.kaggle.com
데이터는 오른쪽 상단에서 Copy API command를 통해 가져오실 수 있습니다
이후 다음처럼 발급받은 username과 key를 입력하도록 하겠습니다
os.environ['KAGGLE_USERNAME'] = 'sihyunlee9604'
os.environ['KAGGLE_KEY'] = 'kaggle_key'
또 아래 명령어를 통해 데이터를 받아오겠습니다
참고로 캐글을 통해 진행하였습니다
!kaggle datasets download -d andrewmvd/heart-failure-clinical-data
!unzip '*.zip'
df = pd.read_csv('heart_failure_clinical_records_dataset.csv')
df.head()
* 데이터 전처리
from sklearn.preprocessing import StandardScaler
X_num = df[['age','creatinine_phosphokinase','ejection_fraction','platelets','serum_creatinine','serum_sodium','time']]
X_cat = df[['anaemia','diabetes','high_blood_pressure','sex','smoking']]
y = df['DEATH_EVENT']먼저 데이터프레임의 칼럼에서 수치형 데이터와 카테고리형 데이터로 나눠주겠습니다.
또한 우리의 타깃 데이터인 Death_Event 칼럼은 y로 지정해 줍니다
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_num)수치형 데이터는 위처럼 fit_transform을 통해 scaling을 해줄 수 있습니다.
또한 변환을 하면 numpy 형식으로 저장되기 때문에 데이터프레임으로 지정해 주겠습니다
X_scaled = pd.DataFrame(data=X_scaled, index=X_num.index, columns=X_num.columns)
X = pd.concat([X_scaled, X_cat],axis=1)
X.head()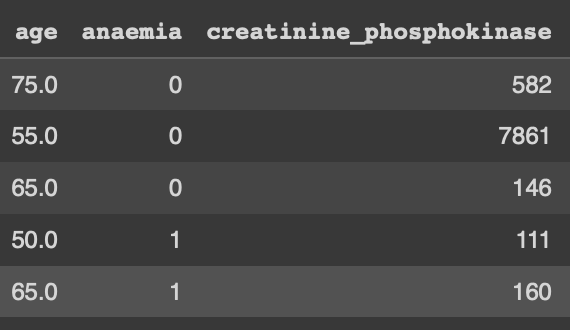
이랬던 데이터가
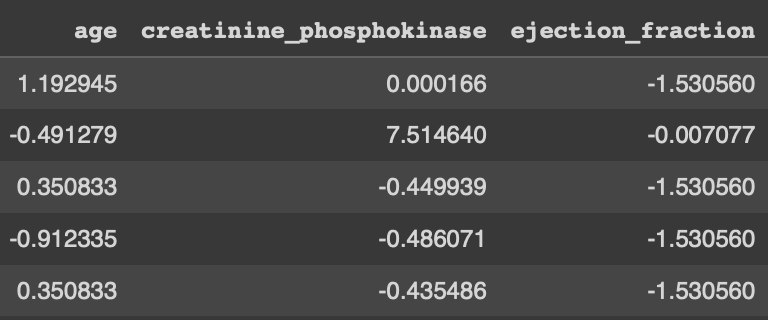
이렇게 변환됐네요
마지막으로 데이터를 학습 데이터 / 테스트 데이터로 분류해 주면 데이터 전처리는 완료가 되겠습니다
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=4234)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
* 모델 선정 및 성능 평가
먼저 LogisticRegression을 사용해 보겠습니다
from sklearn.linear_model import LogisticRegression
model_lr = LogisticRegression(max_iter=1000)
model_lr.fit(X_train, y_train)
from sklearn.metrics import classification_report
pred = model_lr.predict(X_test)
print(classification_report(y_test, pred))
위와 같은 결과가 나왔네요
이번엔 XGBoost를 사용해 보겠습니다
일반적으로 Kaggle에서는 XGBoost를 사용한 결과가 대회에서도 상위권에 있기 때문에
뭘 사용해야 할지 모르시겠다면 XGBoost를 한 번은 해보는 것도 추천드립니다
from xgboost import XGBClassifier
model_xgb = XGBClassifier()
model_xgb.fit(X_train, y_train)
pred = model_xgb.predict(X_test)
print(classification_report(y_test, pred))

위와 같은 성능이 나왔습니다
전체적으로 XGBoost를 사용한 결과가 더 좋게 나온 것을 확인할 수 있습니다
다음은 모델의 결과에 어떤 변수가 영향을 많이 미쳤는지 확인해 보겠습니다
plt.plot(model_xgb.feature_importances_)
7번째 칼럼이 영향을 많이 미쳤다는 것을 확인할 수 있겠습니다
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation=90)
plt.show()
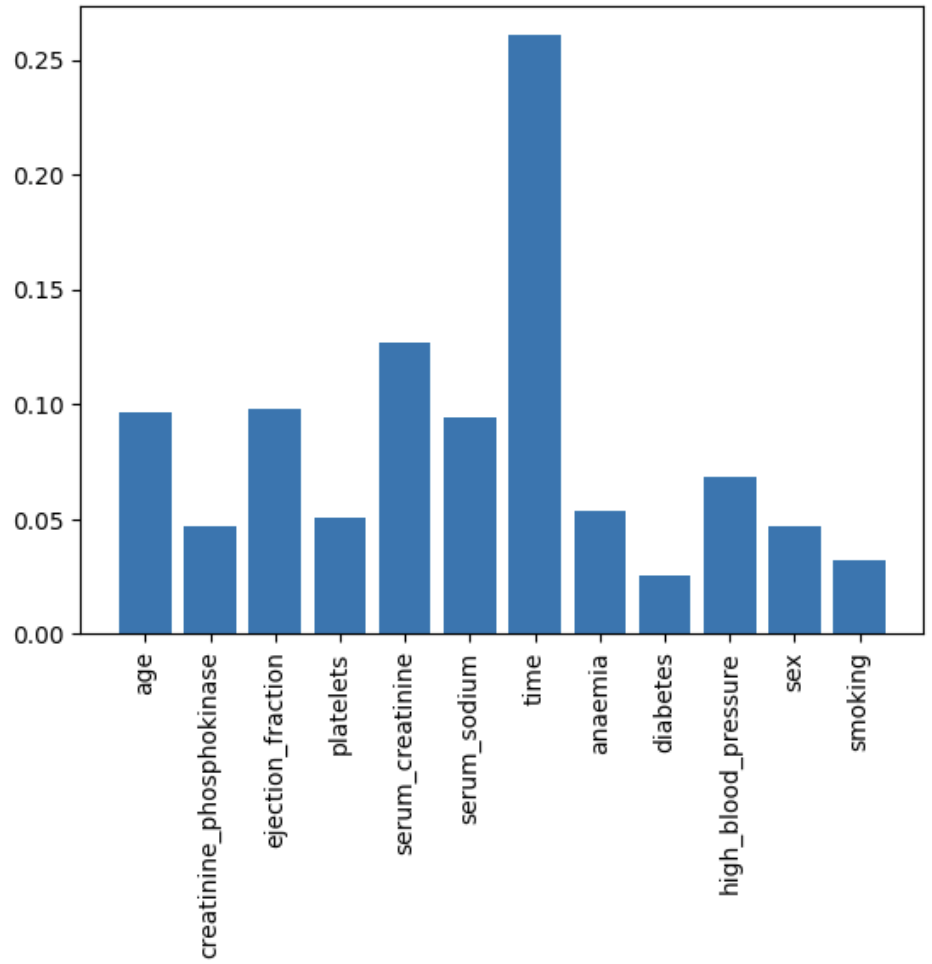
time이라는 속성이 가장 영향을 많이 미쳤다는 것을 확인할 수 있었고,
위 결과를 통해 필요 없는 칼럼은 제거하거나 중요한 속성은 가중치를 주는 등의 방법으로 이후 성능을 올릴 수 있을 것 같습니다.
전체 코드는 아래의 제 깃허브에서 확인해주세요
https://github.com/foxyhyun/STUDY/tree/main/kaggle
GitHub - foxyhyun/STUDY
Contribute to foxyhyun/STUDY development by creating an account on GitHub.
github.com
감사합니다!
'AI > AI' 카테고리의 다른 글
| [AI] R-CNN 내용 정리 (0) | 2023.10.12 |
|---|---|
| [AI] Kaggle 데이터로 데이터 분석하기 _ League of Legends Diamond Ranked Games (0) | 2023.06.17 |
| [AI] Jupyter에서 GPU 사용 여부 확인하기 (0) | 2023.01.02 |
| [AI] Pytorch 개요 및 GPU 사용 여부 체크하기 (0) | 2022.12.22 |
| [AI] Fashion Mnist 데이터셋을 사용한 CNN (0) | 2022.12.18 |



