One-class SVM(anomaly detection)은 비지도 학습 알고리즘으로 데이터셋에서 이상치를 식별하는 데 사용됩니다.
다른 SVM 알고리즘과 달리 훈련을 예상 클래스인 데이터의 한 클래스만 사용합니다.
그런 다음 알고리즘은 일반 클래스와 크게 다른 이상을 식별하는 방법을 학습합니다.
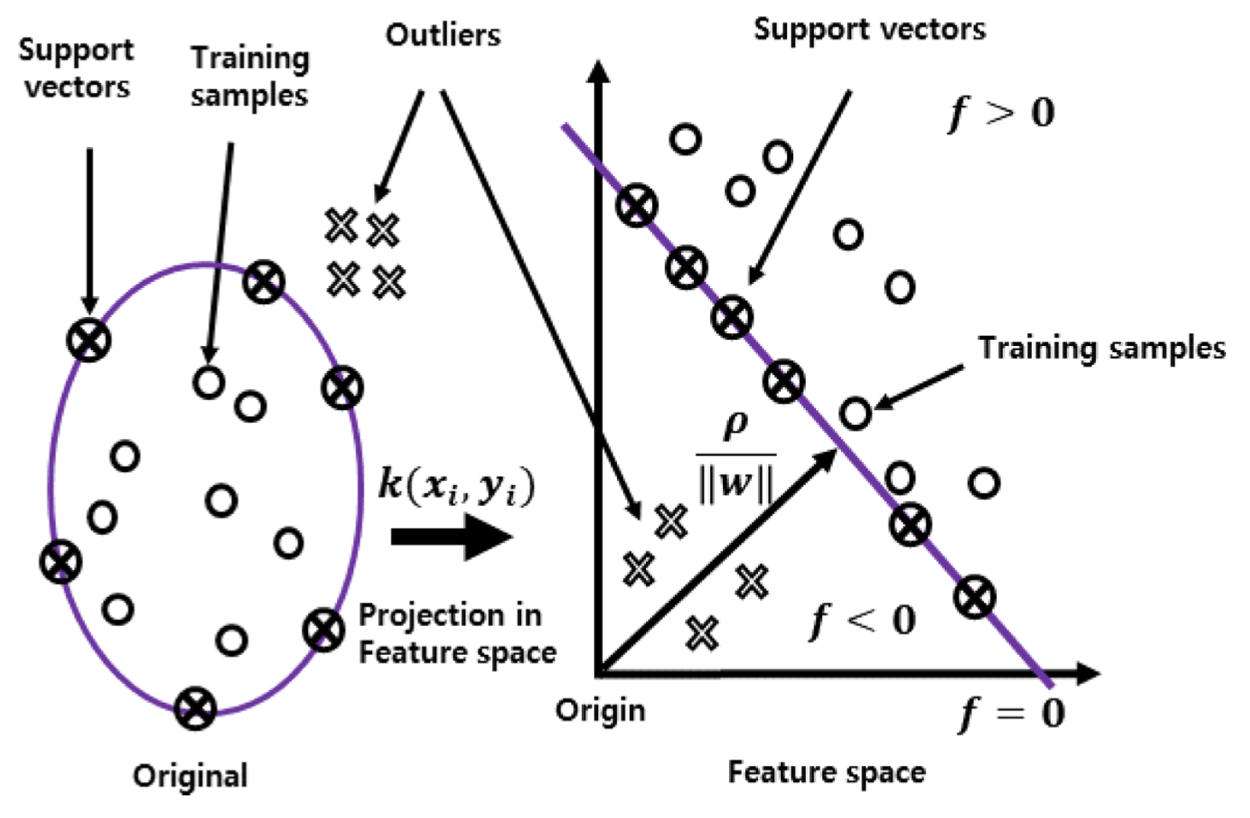
단일 클래스 SVM은 데이터를 N차원 공간으로 변환하여 작동하며 각 차원은 데이터의 기능을 나타냅니다.
그런 다음 알고리즘은 일반 클래스와 이상값을 구분하는 초평면(또는 2D 데이터의 경우 평면)을 그립니다.
초평면은 Support Vector라고 하는 가장 가까운 데이터 점과 초평면 사이의 거리를 최대화하는 방식으로 배치됩니다.
초평면과 가장 가까운 데이터 포인트 사이의 거리를 마진이라고 하며 정상 클래스와 이상값 사이의 분리 품질을 측정하는 데 사용됩니다.
이 알고리즘은 최대 여백을 가진 초평면을 찾는 것을 목표로 하며, 이는 두 클래스 간의 최상의 분리로 이어집니다.
One-class SVM을 사용하려면 예상되는 동작을 나타내는 일반 데이터 세트를 사용하여 알고리즘을 훈련해야 합니다. 그런 다음 알고리즘은 초평면으로부터의 거리를 기준으로 새 데이터 포인트가 정상인지 이상값인지 예측합니다. 데이터 포인트가 초평면에서 멀리 떨어져 있으면 이상값으로 간주됩니다.
장점으로는, 데이터 라벨이 존재하지 않아도 사용가능하며, 저차원이나 고차원의 적은 데이터에서 일반화 능력이 좋은 것이다.
하지만, 단점으로는 데이터가 늘어날수록 연산량이 크게 증가하며 Scaling에 민감하다는 것이 있다.
구현한 코드는 아래와 같습니다.
# One-Class SVM 모델 생성 및 학습
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
# 새로운 데이터가 이상치인지 판단
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print("Train set 정상 데이터의 개수:", len(y_pred_train[y_pred_train == 1]))
print("Train set 비정상 데이터의 개수:", len(y_pred_train[y_pred_train == -1]))
print("Test set 정상 데이터의 개수:", len(y_pred_test[y_pred_test == 1]))
print("Test set 비정상 데이터의 개수:", len(y_pred_test[y_pred_test == -1]))