안녕하세요!
오늘은 교과서처럼 사용되는 데이터셋중 하나인 Fasion MNIST 데이터셋으로 이미지를 분류해볼 예정입니다.
데이터셋에 대한 자세한 내용은 캐글에서 확인하시길 바랍니다.
Fashion MNIST
An MNIST-like dataset of 70,000 28x28 labeled fashion images
www.kaggle.com
바로 시작해볼까요?
먼저 필요한 라이브러리를 불러옵니다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
다음으로 Fasion Mnist 데이터를 불러옵니다.
fashion_mnist = keras.datasets.fashion_mnist
데이터는 각 이미지와 이미지에 대한 설명인 label 데이터로 이루어져있습니다.
학습 데이터와 테스트 데이터로 분리합니다.
이때 이미지의 사이즈를 알기 위해 shape 또한 출력해봅니다.
(train_image, train_label), (test_image, test_label) = fashion_mnist.load_data()
print(f'train Image Shape : {train_image.shape}')
print(f'test Image Shape : {test_image.shape}')
print(f'train Iabel Shape : {train_label.shape}')
print(f'test Iabel Shape : {test_label.shape}')

28 x 28의 흑색 이미지가 학습 데이터에 6만개, 테스트 데이터에 만개 저장되어있고, 각 라벨에 대한 데이터도 동일한 수로 저장되어있네요
각 라벨에 대한 정보를 확인하기 위해 캐글 사이트에 들어가서 보았더니,

의 순서로 저장되어 있네요.
클래스 네임을 동일하게 지정해줍니다.
class_names = [
'T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot'
]
이미지 샘플 하나를 확인해볼까요?
plt.figure()
plt.imshow(train_image[22330])
plt.colorbar()
plt.grid(False)
plt.show()
print(class_names[train_label[22330]])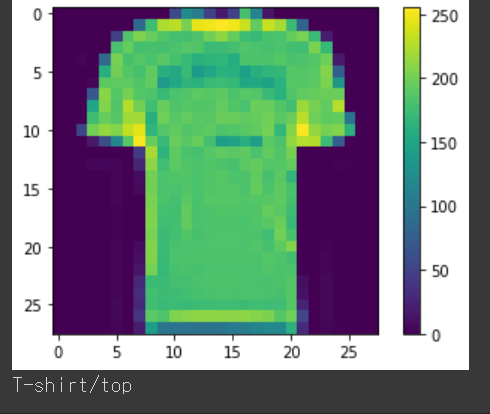
이미지와 라벨이 각 인덱스에 맞게 저장이 잘 되어있네요
더 많은 데이터를 확인하기 위해 훈련 세트에서 처음 25개의 사진을 확인해봅니다
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_image[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_label[i]])
plt.show()

이제 본격적으로 모델에 데이터를 넣어 학습할 준비를 해보겠습니다.
현재 데이터는 이미지의 픽셀값(0~255)로 저장되어 있으니 0~1 사이의 값으로 정규화 해주겠습니다.
train_image = train_image / 255.0
test_image = test_image / 255.0
이제 모델을 설계해봅시다.
이번 시간에는 간단한 모델을 사용하고, 다음 글에서는 CNN을 사용하여 이미지를 분류해보겠습니다.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.summary()
첫 번째로, Flatten 모델을 사용하여 28 x 28 의 데이터를 1차원으로 받아옵니다.
다음으로 Dense 모델에 relu 함수를 사용하여 오차가 급격하게 줄어드는 기울기 소멸 문제를 완화합니다.
마지막으로 총 10개의 class_names가 있으므로 출력층의 노드는 10개로 정해주며 각 노드의 결과값의 총 합이
1이 되도록 하는 softmax를 사용합니다.
다음으로 원핫인코딩을 사용하지 않아도 되며 정수값으로 분류가 가능한 sparse_categorical_entropy를 사용하여 model을 컴파일 해줍니다.
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics=['accuracy'])
이제 모델 학습의 마지막 결과인 fit 를 사용하여 모델을 학습합니다.
model.fit(train_image, train_label, epochs=5)
학습 결과를 확인해보겠습니다.
test_loss, test_acc = model.evaluate(test_image, test_label, verbose=2)
epoch를 낮은 수치인 5로 설정하였기 때문에 정확도가 안좋지만, 적당한 시간으로 학습을 하면 성능이 많이 올라갈 수 있습니다.
이제 마지막으로 예측을 해볼까요?
prediction = model.predict(test_image)
plt.imshow(test_image[0])
np.argmax(prediction[0])
print(class_names[test_label[0]])
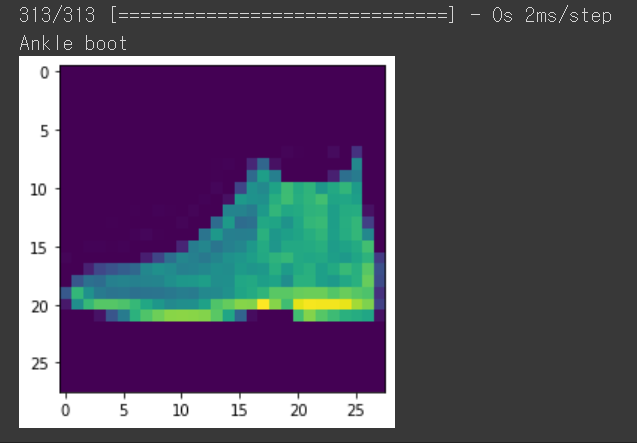
예측 결과가 잘 맞네요
다음 글에서 뵙겠습니다!
'AI > AI' 카테고리의 다른 글
| [AI] Pytorch 개요 및 GPU 사용 여부 체크하기 (0) | 2022.12.22 |
|---|---|
| [AI] Fashion Mnist 데이터셋을 사용한 CNN (0) | 2022.12.18 |
| [AI] RNN(Recurrent Neural Network)와 LSTM, GRU의 개념알기 (0) | 2022.12.17 |
| [AI] CNN 구현 시 고려해야할 사항들 (1) | 2022.12.07 |
| [AI] 전이학습 | Cifar10 | MobileNetV2 (0) | 2022.11.23 |



